Apache Kafka is a high-throughput, high-availability, and scalable solution chosen by the world’s top companies for uses such as event streaming, stream processing, log aggregation, and more. Kafka runs on the platform of your choice, such as Kubernetes or ECS, as a cluster of one or more Kafka nodes. A Kafka cluster will be initialized with zero or more topics, which you can think of as message channels or queues. Clients can connect to Kafka to publish messages to topics or to consume messages from topics the client is subscribed to.
Docker is an application that uses virtualization to run containerized applications on a host machine. Containerization enables users to build, run, and test applications completely separately while still allowing them to communicate across a network. Importantly, containerization enables application portability so that the same application can be run on your local machine, a Kubernetes cluster, AWS, and more.
Both Kafka and Docker are pretty complex technologies, and it can be difficult to determine where to get started once you’re sure that they’re the right fit for the problem you’re solving. To keep things simple, we’ll create one producer, one consumer, and one Kafka instance.
Project dependencies for Kafka and Docker
In this tutorial, we’ll start by using Docker Compose to build, run, and test locally. We’ll also walk through how to use kubectl to deploy our application to the cloud. Last, we’ll walk through how we can use Architect to seamlessly deploy our application locally and to the cloud using the same configuration. Before getting started, be sure to have the following dependencies installed locally:
- Docker
- Docker-compose
- A Docker Hub account
- npm
- Architect CLI
- kubectl
- A Kubernetes cluster on DigitalOcean or elsewhere
- A free Architect account
As mentioned previously, this part of the tutorial will contain multiple services running on your local machine. You can use docker-compose to run them all at once and stop them all when you’re ready. Let’s get going!
Build the publisher service in Node for Kafka with Docker
You can clone this repo to access the code used in this blog post, or you can follow along with the following steps. Start by creating a project directory with two folders inside it named “subscriber” and “publisher.” These folders will contain the application code, supporting Node files, and Dockerfiles that will be needed to build the apps that will communicate with Kafka.
The publisher service will be the one that generates messages that will be published to a Kafka topic. For simplicity, the service will generate a simple message at an interval of five seconds. Inside of the “publisher” folder, add a new file called index.js with the following contents:
const kafka = require('kafka-node');
const client = new kafka.KafkaClient({
kafkaHost:
process.env.ENVIRONMENT === 'local'
? process.env.INTERNAL_KAFKA_ADDR
: process.env.EXTERNAL_KAFKA_ADDR,
});
const Producer = kafka.Producer;
const producer = new Producer(client);
producer.on('ready', () => {
setInterval(() => {
const payloads = [
{
topic: process.env.TOPIC,
messages: [`${process.env.TOPIC}_message_${Date.now()}`],
},
];
producer.send(payloads, (err, data) => {
if (err) {
console.log(err);
}
console.log(data);
});
}, 5000);
});
producer.on('error', err => {
console.log(err);
});Save and close the index. We’ll also need some supporting modules installed to our Docker container when it’s built. Also, in the “publisher” folder, create a package.json with the JSON here:
{
"name": "publisher",
"version": "0.1.0",
"main": "index.js",
"scripts": {
"start": "node index.js"
},
"license": "ISC",
"dependencies": {
"body-parser":"^1.20.1",
"cors": "^2.8.5",
"express": "^4.18.2",
"kafka-node": "^5.0.0",
"winston": "^3.8.2"
}
}Save and close the package.json. Alongside the last two files, we’ll need a package-lock.json, which can be created with the following command:
npm i --package-lock-onlyThe last file to create for the publisher will pull everything together, and that’s the Dockerfile. Create the Dockerfile alongside the other three files that were just created and add the following:
FROM node:18-alpine
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "npm", "start" ]Save and close the file. Line by line, the Dockerfile that was just added to the folder will instruct the Docker daemon to build the publisher image like so:
- Pull the Docker image
node:12-alpineas the base container image - Set the working directory to
/usr/src/app. Subsequent commands will be run in this folder - Copy the
package.jsonandpackage-lock.jsonthat were just created into the/usr/src/appdirectory - Run
npm installto install node modules - Copy the rest of the files from the directory on the home machine to
/usr/src/app. Importantly, this includes theindex.js - Run the command
npm startin the container.npmis already installed on thenode:12-alpineimage, and thestartscript is defined in thepackage.json
Build the subscriber service for Kafka with Docker
The subscriber service will be built very similarly to the publisher service and will consume messages from the Kafka topic. Messages will be consumed as frequently as they’re published, again, every five seconds in this case. To start, add a file titled index.js to the “subscriber” folder and add the following code:
const kafka = require('kafka-node');
const client = new kafka.KafkaClient({
kafkaHost:
process.env.ENVIRONMENT === 'local'
? process.env.INTERNAL_KAFKA_ADDR
: process.env.EXTERNAL_KAFKA_ADDR,
});
const Consumer = kafka.Consumer;
const consumer = new Consumer(
client,
[
{
topic: process.env.TOPIC,
partition: 0,
},
],
{
autoCommit: false,
},
);
consumer.on('message', message => {
console.log(message);
});
consumer.on('error', err => {
console.log(err);
});Save and close the index. Also, similar to the publisher, we’ll need a package.json file like this:
{
"name": "subscriber",
"version": "0.1.0",
"main": "index.js",
"scripts": {
"start": "node index.js"
},
"author": "Architect.io",
"license": "ISC",
"dependencies": {
"body-parser": "^1.20.1",
"cors": "^2.8.5",
"express": "^4.18.2",
"kafka-node": "^5.0.0",
"winston": "^3.8.2"
}
}Save and close the package.json, then create a package-lock.json using the same command as before:
npm i --package-lock-onlyThe subscriber needs one extra file that the publisher doesn’t, and that’s a file we’ll call wait-for-it.js. Create the file and add the following:
const kafka = require('kafka-node');
const client = new kafka.KafkaClient({
kafkaHost:
process.env.ENVIRONMENT === 'local'
? process.env.INTERNAL_KAFKA_ADDR
: process.env.EXTERNAL_KAFKA_ADDR,
});
const Admin = kafka.Admin;
const child_process = require('child_process');
const admin = new Admin(client);
const interval_id = setInterval(() => {
admin.listTopics((err, res) => {
if (res[1].metadata[process.env.TOPIC]) {
console.log('Kafka topic created');
clearInterval(interval_id);
child_process.execSync('npm start', { stdio: 'inherit' });
} else {
console.log('Waiting for Kafka topic to be created');
}
});
}, 1000);This file will be used in the Docker container to ensure that the consumer doesn’t attempt to consume messages from the topic before the topic has been created. Each second, it will check whether the topic exists, and when Kafka has started, and the topic is finally created, the subscriber will start. Last, create the Dockerfile in the “subscriber” folder with the following snippet:
FROM node:18-alpine
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "node", "wait-for-it.js" ]The subscriber’s Dockerfile is the same as the publisher’s, with the one difference noted above. The command that starts the container uses the wait-for-it.js file rather than the index. Save and close the Dockerfile.
The docker-compose file for the Kafka stack
The docker-compose file is where the publisher, subscriber, Kafka, and Zookeeper services will be tied together. Zookeeper is a service that is used to synchronize Kafka nodes within a cluster. Zookeeper deserves a post all of its own, and because we only need one node in this tutorial I won’t be going in-depth on it here. In the root of the project alongside the “subscriber” and “publisher” folders, create a file called docker-compose.yml and add this configuration:
version: '3'
services:
zookeeper:
ports:
- '50000:2181'
image: zookeeper:3.5.9
kafka:
ports:
- '50001:9092'
- '50002:9093'
depends_on:
- zookeeper
environment:
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENERS: 'INTERNAL://:9092'
KAFKA_ADVERTISED_LISTENERS: 'INTERNAL://:9092'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'INTERNAL:PLAINTEXT'
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: '1'
KAFKA_CREATE_TOPICS: 'example-topic:1:1'
KAFKA_ADVERTISED_HOST_NAME: host.docker.internal # change to 172.17.0.1 if running on Ubuntu
image: 'wurstmeister/kafka:2.13-2.8.1'
volumes:
- '/var/run/docker.sock:/var/run/docker.sock'
publisher:
depends_on:
- kafka
environment:
TOPIC: example-topic
ENVIRONMENT: local
INTERNAL_KAFKA_ADDR: 'kafka:9092'
build:
context: ./publisher
subscriber:
depends_on:
- kafka
environment:
TOPIC: example-topic
ENVIRONMENT: local
INTERNAL_KAFKA_ADDR: 'kafka:9092'
build:
context: ./subscriber
volumes: {}Note that the services block of the docker-compose contains four keys under which we define specific properties for each service. Below is a service-by-service walkthrough of what each property and its sub-properties are used for.
Zookeeper
The ports property instructs Zookeeper to expose itself to Kafka on port 2181 inside of the Docker network. Zookeeper is also available to the host machine on port 50000. The image property instructs the Docker daemon to pull the latest version of the image zookeeper.
Kafka
The kafka service block includes configuration that will be passed to Kafka running inside of the container, among other properties that will enable communication between the Kafka service and other containers.
ports– Kafka exposes itself on two ports internal to the Docker network, 9092 and 9093. It is also exposed to the host machine on ports 50001 and 50002.depends_on– Kafka depends on Zookeeper to run, so its key is included in thedepends_onblock to ensure that Docker will start Zookeeper before Kafka.environment– Kafka will pick up the environment variables in this block once the container starts. All configuration options except forKAFKA_CREATE_TOPICSwill be added to a Kafka broker config and applied on startup. The variableKAFKA_CREATE_TOPICSis used by the Docker image itself, not Kafka, to make working with Kafka easier. Topics defined by this variable will be created when Kafka starts without any external instructions.image– This field instructs the Docker daemon to pull version 2.13-2.8.1 of the image wurstmeister/kafka .volumes– This is a requirement by the Docker image to use the Docker CLI when starting Kafka locally.
Publisher
Most configuration in the publisher block specifies how the publisher should communicate with Kafka. Note that the depends_on property ensures that the publisher will start after Kafka.
depends_on– The publisher service naturally depends on Kafka, so it’s included in the dependency array.environment– These variables are used by the code in theindex.jsof the publisher.TOPIC– This is the topic that messages will be published to. Note that it matches the topic that will be created by the Kafka container.ENVIRONMENT– This environment variable determines inside the index file on what port the service will communicate with Kafka. The ternary statement that it is used in exists to use the same code for both local and remote deployments.INTERNAL_KAFKA_ADDR– The publisher will connect to Kafka on this host and port.build– The context inside tells the Docker daemon where to locate the Dockerfile that describes how the service will be built and run, along with supporting code and other files that will be used inside of the container.
Subscriber
Most of the docker-compose configuration for the subscriber service is identical to that of the publisher service. The one difference is that the context tells the Docker daemon to build from the “subscriber” directory, where its Dockerfile and supporting files were created.
Run the example stack
Finally, the moment we’ve all been waiting for, running the services! All that’s needed now is to run the command below from the root directory of the project:
docker-compose upThat’s it! Once all of the services start up and the Kafka topic is created, the output from the publisher and subscriber services will look like this:
publisher_1 | { 'example-topic': { '0': 0 } }
subscriber_1 | Kafka topic created
subscriber_1 |
subscriber_1 | > @architect-examples/event-subscriber@0.1.0 start /usr/src/app
subscriber_1 | > node index.js
subscriber_1 |
subscriber_1 | {
subscriber_1 | topic: 'example-topic',
subscriber_1 | value: 'example-topic_message_1610477237480',
subscriber_1 | offset: 0,
subscriber_1 | partition: 0,
subscriber_1 | highWaterOffset: 1,
subscriber_1 | key: null
subscriber_1 | }
subscriber_1 | {
subscriber_1 | topic: 'example-topic',
subscriber_1 | value: 'example-topic_message_1610477242483',
subscriber_1 | offset: 1,
subscriber_1 | partition: 0,
subscriber_1 | highWaterOffset: 2,
subscriber_1 | key: null
subscriber_1 | }
publisher_1 | { 'example-topic': { '0': 1 } }New messages will continue to be published and consumed until the docker-compose process is stopped by pressing ctrl/cmd+C in the same terminal that it was started in.
Run Kafka in the cloud on Kubernetes
Running Kafka locally can be useful for testing and iterating, but where it’s most useful is, of course, the cloud. This section of the tutorial will guide you through deploying the same application that was just deployed locally to your Kubernetes cluster. Note that most services charge some amount of money by default for running a Kubernetes cluster, though occasionally you can get free credits when you sign up. For the most straightforward setup of a cluster, you can run your Kubernetes cluster with Digital Ocean. For the cluster to pull the Docker images that you will be building, a Docker Hub account will be useful, where you can host multiple free repositories. The same code and Docker images will be used from the previous part of the tutorial.
Build and push the images to Docker Hub
For the Kubernetes cluster to pull the Docker images, they’ll need to be pushed to a repository in the cloud where they can be accessed. Docker Hub is the most frequently used cloud-hosted repository, and the images here will be made public for ease of use in this tutorial. To start, be sure that you have a Docker Hub account, then enter the following in a terminal:
docker loginEnter your Docker Hub username (not email) and password when prompted. You should see the message – Login Succeeded – which indicates that you’ve successfully logged in to Docker Hub in the terminal. The next step is to push the images that will need to be used in the Kubernetes cluster. From the root of the project, navigate to the publisher directory and build and tag the publisher service with the following command:
docker build . -t <your_docker_hub_username>/publisher:latestYour local machine now has a Docker image tagged as <your_docker_hub_username>/publisher:latest, which can be pushed to the cloud. You might have also noticed that the build was faster than the first time the publisher was built. This is because Docker caches image layers locally, and if you didn’t change anything in the publisher service, it doesn’t need to be rebuilt completely. Now, push the tagged image with the command:
docker push <your_docker_hub_username>/publisher:latestYour custom image is now hosted publicly on the internet! Navigate to https://hub.docker.com/repository/docker/<your_docker_hub_username>/publisher and login if you’d like to view it. Now, navigate to the subscriber folder and do the same for the subscriber service with two similar commands:
docker build . -t <your_docker_hub_username>/subscriber:latest
docker push <your_docker_hub_username>/subscriber:latestAll of the images needed to run the stack on a Kubernetes cluster should now be available publicly. Fortunately, Kafka and Zookeeper didn’t need to be pushed anywhere, as the images are already public.
Deploy your stack to Kubernetes
Once you have a Kubernetes cluster created on Digital Ocean or wherever you prefer, and you’ve downloaded the cluster’s kubeconfig or set your Kubernetes context, you’re ready to deploy the publisher, consumer, Kafka, and Zookeeper. Be sure that the cluster also has the Kubernetes dashboard installed. On Digital Ocean, the dashboard will be preinstalled.
Deploying to Kubernetes in the next steps will also require the Kubernetes CLI, kubectl to be installed to your local machine. Once the prerequisites are complete, the next steps will be creating and deploying Kubernetes manifests. These manifests will be for a namespace, deployments, and services. In the root of the project, create a directory called “kubernetes” and navigate to that directory. For organization, all manifests will be created here. Start by creating a file called namespace.yml. Within Kubernetes, the namespace will group all of the resources created in this tutorial.
apiVersion: v1
kind: Namespace
metadata:
name: kafka-example
labels:
name: kafka-exampleSave and close the file. To create the namespace within the Kubernetes cluster, kubectl will be used. Run the command below:
kubectl create -f namespace.yml --kubeconfig=<kubeconfig_file_for_your_cluster>If the namespace was created successfully, the message namespace/kafka-example created will be printed to the console.
Before deployments are created, Kubernetes services are required to allow traffic to the pods that others depend on. To do this, two services will be created. One will allow traffic to the Kafka pod on its exposed ports, 9092 and 9093, and the other will allow traffic to the Zookeeper pod on its exposed port, 2181. These will allow the publisher and subscriber to send traffic to Kafka and Kafka to send traffic to Zookeeper, respectively. Still in the k8s directory, start by creating a file called kafka-service.yml with the following yml:
kind: Service
apiVersion: v1
metadata:
name: example-kafka
namespace: kafka-example
labels:
app: example-kafka
spec:
ports:
- name: external
protocol: TCP
port: 9093
targetPort: 9093
- name: internal
protocol: TCP
port: 9092
targetPort: 9092
selector:
app: example-kafka
type: ClusterIP
sessionAffinity: NoneCreate the service in the cluster by running the command below:
kubectl create -f kafka-service.yml --kubeconfig=<kubeconfig_file_for_your_cluster>kubectl should confirm that the service has been created. Now, create the other service by first creating a file called zookeeper-service.yml. Add the following contents to that file:
kind: Service
apiVersion: v1
metadata:
name: example-zookeeper
namespace: kafka-example
labels:
app: example-zookeeper
spec:
ports:
- name: main
protocol: TCP
port: 2181
targetPort: 2181
selector:
app: example-zookeeper
type: ClusterIP
sessionAffinity: NoneCreate the service within the cluster with the command:
kubectl create -f zookeeper-service.yml --kubeconfig=<kubeconfig_file_for_your_cluster>Next, four deployments will need to be created inside the new namespace, one for each service. Start by creating a file called zookeeper-deployment.yml and add the following yml:
kind: Deployment
apiVersion: apps/v1
metadata:
name: example-zookeeper
namespace: kafka-example
labels:
app: example-zookeeper
spec:
replicas: 1
selector:
matchLabels:
app: example-zookeeper
template:
metadata:
labels:
app: example-zookeeper
spec:
containers:
- name: example-zookeeper
image: jplock/zookeeper
ports:
- containerPort: 2181
protocol: TCP
imagePullPolicy: IfNotPresent
restartPolicy: Always
dnsPolicy: ClusterFirst
schedulerName: default-scheduler
enableServiceLinks: true
strategy:
type: RollingUpdateSave the contents and run the command below to create the deployment in the kafka-example namespace:
kubectl create -f zookeeper-deployment.yml --kubeconfig=<kubeconfig_file_for_your_cluster>When the deployment has been created successfully, deployment.apps/example-zookeeper created will be printed. The next step will be creating and deploying the manifest for Kafka. Create the file kafka-deployment.yml and add:
kind: Deployment
apiVersion: apps/v1
metadata:
name: example-kafka
namespace: kafka-example
labels:
app: example-kafka
spec:
replicas: 1
selector:
matchLabels:
app: example-kafka
template:
metadata:
labels:
app: example-kafka
spec:
containers:
- name: example-kafka
image: 'wurstmeister/kafka:2.13-2.8.1'
ports:
- containerPort: 9093
protocol: TCP
- containerPort: 9092
protocol: TCP
env:
- name: KAFKA_ADVERTISED_LISTENERS
value: INTERNAL://:9092,EXTERNAL://example-kafka.kafka-example.svc.cluster.local:9093
- name: KAFKA_CREATE_TOPICS
value: example-topic:1:1
- name: KAFKA_INTER_BROKER_LISTENER_NAME
value: INTERNAL
- name: KAFKA_LISTENERS
value: INTERNAL://:9092,EXTERNAL://:9093
- name: KAFKA_LISTENER_SECURITY_PROTOCOL_MAP
value: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
- name: KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR
value: '1'
- name: KAFKA_ZOOKEEPER_CONNECT
value: example-zookeeper.kafka-example.svc.cluster.local:2181
imagePullPolicy: IfNotPresent
restartPolicy: Always
dnsPolicy: ClusterFirst
schedulerName: default-scheduler
enableServiceLinks: true
strategy:
type: RollingUpdateSave and close the file. Similar to the Zookeeper deployment, run the command below in a terminal:
kubectl create -f kafka-deployment.yml --kubeconfig=<kubeconfig_file_for_your_cluster>deployment.apps/example-kafka created should have been printed to the console. The last two deployments to be created will be the subscriber and publisher services. Create publisher-deployment.yml with the contents and be sure to replace <your_docker_hub_username> with your own username:
kind: Deployment
apiVersion: apps/v1
metadata:
name: example-publisher
namespace: kafka-example
labels:
app: example-publisher
spec:
replicas: 1
selector:
matchLabels:
app: example-publisher
template:
metadata:
labels:
app: example-publisher
spec:
containers:
- name: example-publisher
image: '<your_docker_hub_username>/publisher:latest'
imagePullPolicy: Always
env:
- name: ENVIRONMENT
value: prod
- name: EXTERNAL_KAFKA_ADDR
value: example-kafka.kafka-example.svc.cluster.local:9093
- name: TOPIC
value: example-topic
restartPolicy: Always
dnsPolicy: ClusterFirst
schedulerName: default-scheduler
enableServiceLinks: true
strategy:
type: RollingUpdateRun kubectl create -f publisher-deployment.yml --kubeconfig=<kubeconfig_file_for_your_cluster> to create the deployment for the publisher and make sure that kubectl prints a message letting you know that it’s been created. The last deployment to create is the subscriber, which will be created in the same way as the other services. Create the file subscriber-deployment.yml and add the following configuration, being sure to replace <your_docker_hub_username>:
kind: Deployment
apiVersion: apps/v1
metadata:
name: example-subscriber
namespace: kafka-example
labels:
app: example-subscriber
spec:
replicas: 1
selector:
matchLabels:
app: example-subscriber
template:
metadata:
labels:
app: example-subscriber
spec:
containers:
- name: example-subscriber
image: '<your_docker_hub_username>/subscriber:latest'
imagePullPolicy: Always
env:
- name: ENVIRONMENT
value: prod
- name: EXTERNAL_KAFKA_ADDR
value: example-kafka.kafka-example.svc.cluster.local:9093
- name: TOPIC
value: example-topic
restartPolicy: Always
dnsPolicy: ClusterFirst
schedulerName: default-scheduler
enableServiceLinks: true
strategy:
type: RollingUpdateFor the last of the deployments, create the subscriber by running kubectl create -f subscriber-deployment.yml --kubeconfig=<kubeconfig_file_for_your_cluster>. If you now navigate to the Kubernetes dashboard for your cluster, you should see that all four deployments have been created, which have in turn created four pods. Each pod runs the container referred to by the image field in its respective deployment.
Wait for a success message to print to the console. Now that all required services and deployments are created feel free to navigate to the Kubernetes dashboard to view the running pods. Navigate to the running example-subscriber pod and view the logs to see that it’s consuming messages from the topic.
If you’re satisfied with your work and want to destroy all of the Kubernetes resources that you just created, use the following command to clean up:
kubectl delete namespace kafka-example --kubeconfig=<kubeconfig_file_for_your_cluster>Whew! That was a little complicated and took quite a few commands and files to run. What if everything that was done could be compressed into a single, short file? What if the entire stack could be created in Kubernetes with a single command? Continue to find out how easy deploying a Kafka-centric stack both locally and on Kubernetes can be.
Run Kafka locally with Architect
The Architect platform can dramatically simplify deployments of any architecture to both local and cloud environments. Just define a component in a single file representing the services that should be deployed, and that component can be deployed anywhere. The Kafka example which you just ran locally can be defined in the following manner as an Architect component:
name: kafka
homepage: https://github.com/architect-community/node-kafka
services:
zookeeper:
image: zookeeper:3.5.9
interfaces:
main: 2181
kafka:
image: wurstmeister/kafka:2.13-2.8.1
interfaces:
internal: 9092
external: 9093
environment:
KAFKA_ZOOKEEPER_CONNECT:
${{ services.zookeeper.interfaces.main.host }}:${{ services.zookeeper.interfaces.main.port
}}
KAFKA_LISTENERS:
INTERNAL://:${{ services.kafka.interfaces.internal.port }},EXTERNAL://:${{
services.kafka.interfaces.external.port }}
KAFKA_ADVERTISED_LISTENERS:
INTERNAL://:9092,EXTERNAL://${{ services.kafka.interfaces.external.host }}:${{
services.kafka.interfaces.external.port }}
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CREATE_TOPICS: architect:1:1
debug:
volumes:
docker:
mount_path: /var/run/docker.sock
host_path: /var/run/docker.sock
environment:
KAFKA_ADVERTISED_HOST_NAME: host.docker.internal # change to 172.17.0.1 if running on Ubuntu
KAFKA_LISTENERS: INTERNAL://:9092
KAFKA_ADVERTISED_LISTENERS: INTERNAL://:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT
publisher:
build:
context: ./publisher/
interfaces:
environment:
EXTERNAL_KAFKA_ADDR:
${{ services.kafka.interfaces.external.host }}:${{ services.kafka.interfaces.external.port
}}
TOPIC: architect
ENVIRONMENT: prod
debug:
environment:
INTERNAL_KAFKA_ADDR:
${{ services.kafka.interfaces.internal.host }}:${{ services.kafka.interfaces.internal.port
}}
ENVIRONMENT: local
subscriber:
build:
context: ./subscriber/
interfaces:
environment:
EXTERNAL_KAFKA_ADDR:
${{ services.kafka.interfaces.external.host }}:${{ services.kafka.interfaces.external.port
}}
TOPIC: architect
ENVIRONMENT: prod
debug:
environment:
INTERNAL_KAFKA_ADDR:
${{ services.kafka.interfaces.internal.host }}:${{ services.kafka.interfaces.internal.port
}}
ENVIRONMENT: localCopy and paste the yml above into a file called “architect.yml” in the project’s root directory. To run the Kafka component locally, run the command below in the project’s root directory:
architect dev architect.ymlThe same information should be printed to the console as when the stack was run directly with docker-compose. When you’re ready, press Ctrl/Cmd+C to stop the running application. As mentioned before, an Architect component can be deployed both locally and to any cloud environment. You can run this stack on Architect’s free community cloud by running a few commands from the project’s top-level directory.
First, run the command below to login to your free Architect account from the Architect CLI. A web browser window will be displayed asking for your credentials.
architect loginNext let’s create an environment to run our application in.
architect environment:create --account=<your_free_architect_account_name> kafka-demoThen run the command below to deploy the stack to the Kubernetes environment that comes with your free Architect account. Don’t forget to replace <your_free_architect_account_name> with the name you used when you created your Architect account.
architect deploy architect.yml --account <your_free_architect_account_name> --environment kafka-demoEnter “‘Y” at the next prompt to kick off the deployment. When it completes, you’ll see “Deploying… done” in your terminal. You can login to Architect, select “environments” and then “kafka-demo” to see the containers you just deployed to Architect’s community cloud.
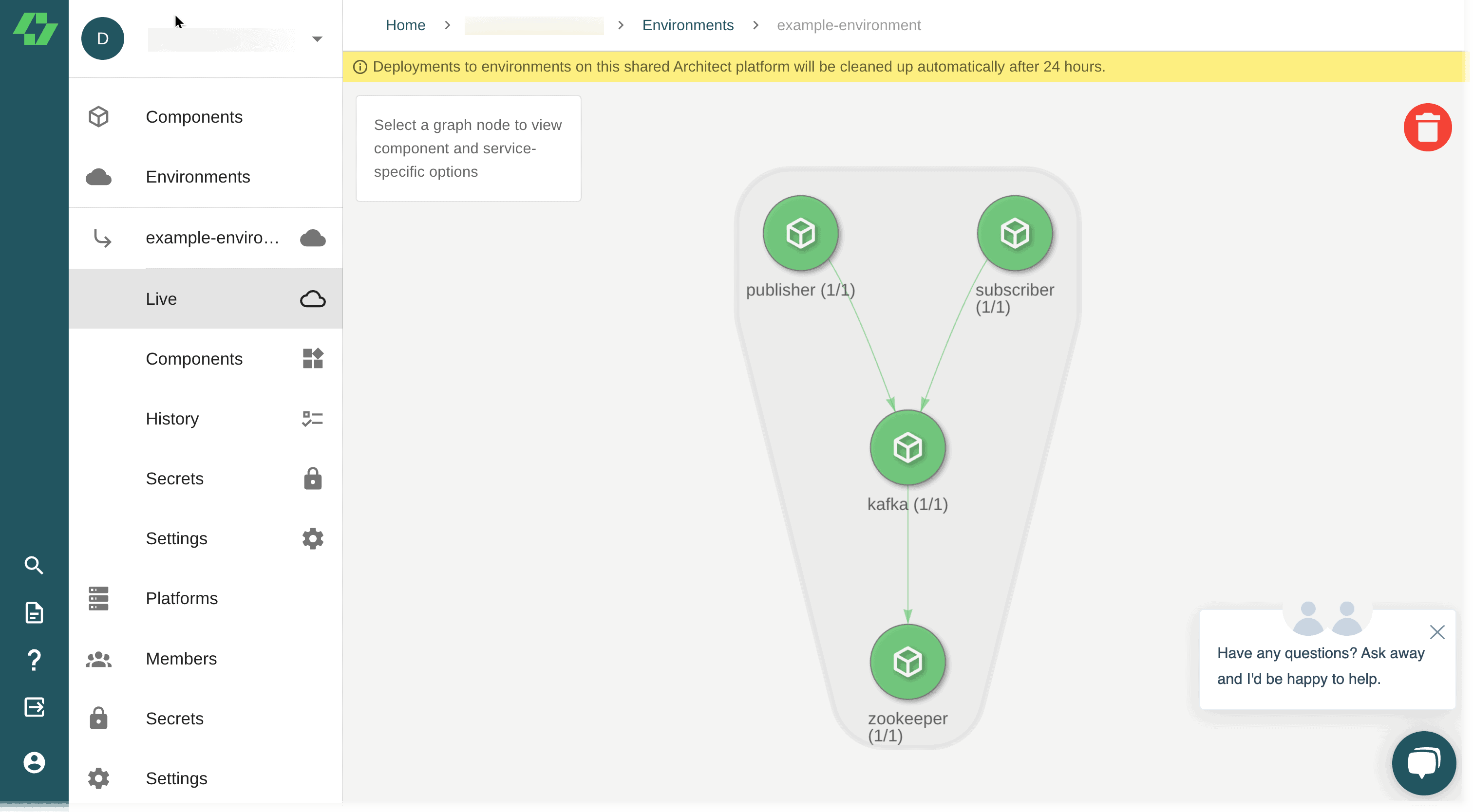
A few clicks, and that’s it! The same stack that could be run locally is running in a Kubernetes cluster in the cloud. If you would like to explore more, feel free to register your own cluster as a platform with the Architect Cloud!
Finally, to clean up this environment and break down your deployed services, use:
architect destroy -a <your-account-name> -e kafka-demoLearn more about safe, fast deployments with Docker and Architect
Kafka is a powerful yet complicated application that takes careful configuration to get running properly. Fortunately, there are a few robust tools like docker-compose and Architect to enable smooth deployments locally and in the cloud. If you’d like to understand more about how Architect can help you expedite both local and remote deployments, check out the docs and sign up!
For more reading, check out some of our other tutorials!
- Implement RabbitMQ on Docker in 20 Minutes
- Deploy your Django app with Docker
- A Developer’s Guide to GitOps
If you have any questions or comments, don’t hesitate to reach out to the team on Twitter @architect_team!
Add your thoughts